Tutorial
One-dimensional Random Walk
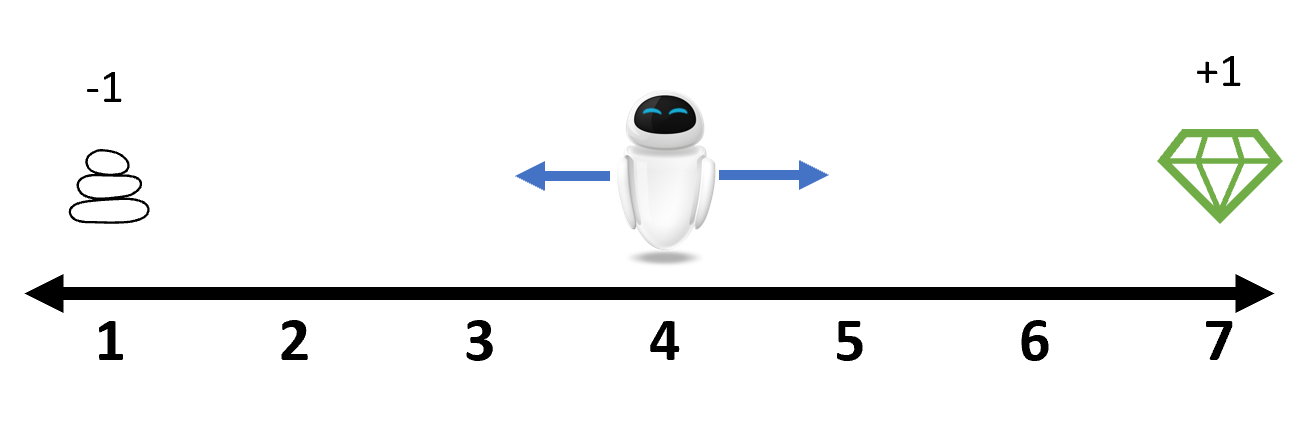
Suppose that an agent is placed at the position 4 on the following number line. At each step, it can either move left or right. Here we use the integer 1 and 2 to represent them respectively. Whenever it reaches the end of the line, the game is terminated. A reward of +1 is received if it stops at position 7 and a punishment of -1 is received if it stops at position 1. In other cases, the reward is 0.
This environment is already provided as RandomWalk1D. Let's get familiar with some basic interfaces first.
julia> using ReinforcementLearningjulia> env = RandomWalk1D()# RandomWalk1D ## Traits | Trait Type | Value | |:----------------- | --------------------:| | NumAgentStyle | SingleAgent() | | DynamicStyle | Sequential() | | InformationStyle | PerfectInformation() | | ChanceStyle | Deterministic() | | RewardStyle | TerminalReward() | | UtilityStyle | GeneralSum() | | ActionStyle | MinimalActionSet() | | StateStyle | Observation{Int64}() | | DefaultStateStyle | Observation{Int64}() | | EpisodeStyle | Episodic() | ## Is Environment Terminated? No ## State Space `Base.OneTo(7)` ## Action Space `Base.OneTo(2)` ## Current State ``` 4 ```julia> S = state_space(env)Base.OneTo(7)julia> s = state(env) # the initial position4julia> A = action_space(env)Base.OneTo(2)julia> is_terminated(env)falsejulia> while true act!(env, rand(A)) is_terminated(env) && break endjulia> state(env)1julia> reward(env)-1.0
You can find more detailed explanation of the functions used above at ReinforcementLearningBase.jl.
In this simple game, we are interested in finding out an optimum policy for the agent to gain the maximum cumulative reward in an episode. The random selection policy above is a good benchmark. The only thing left is to calculate the total reward. Because such workflow is so common in reinforcement learning tasks, an extended Base.run function is provided so that we can design the workflow in a descriptive pattern.
julia> run( RandomPolicy(), RandomWalk1D(), StopAfterNEpisodes(10), TotalRewardPerEpisode() )TotalRewardPerEpisode{Val{true}, Float64}([-1.0, 1.0, 1.0, 1.0, -1.0, 1.0, -1.0, 1.0, -1.0, -1.0], 0.0, true)
Next, let's introduce one of the most common policies, the QBasedPolicy. It contains two parts, a state-action value function to estimate the estimated value of each state-action pair and an explorer to select which action to take based on the result of the state-action values.
julia> NS = length(S)7julia> NA = length(A)2julia> policy = QBasedPolicy( learner = TDLearner( TabularQApproximator( n_state = NS, n_action = NA, ), :SARS ), explorer = EpsilonGreedyExplorer(0.1) )QBasedPolicy( TDLearner( TabularQApproximator{Matrix{Float64}}([0.0 0.0 … 0.0 0.0; 0.0 0.0 … 0.0 0.0]), # 14 parameters (all zero) 1.0, 0.01, 0, ), )
Here we choose the TDLearner and the EpsilonGreedyExplorer. But you can also replace them with some other Q value learners or value explorers. Similar to what we did before, we can apply this policy to the env to estimate its performance.
julia> run( policy, RandomWalk1D(), StopAfterNEpisodes(10), TotalRewardPerEpisode() )TotalRewardPerEpisode{Val{true}, Float64}([-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], 0.0, true)
Until now, the policies we've seen are very simple ones. There're no optimizations involved in these policies. We call that they are in the actor mode, which means they only generate actions statically at each step. However, our main goal in reinforcement learning is to improve our policy during the interactions with the environments. We say the policy is in the learner mode in this case. To run policies in the learner mode, a dedicated wrapper policy Agent is provided.
julia> using ReinforcementLearningTrajectoriesERROR: ArgumentError: Package ReinforcementLearningTrajectories not found in current path, maybe you meant `import/using .ReinforcementLearningTrajectories`. - Otherwise, run `import Pkg; Pkg.add("ReinforcementLearningTrajectories")` to install the ReinforcementLearningTrajectories package.julia> trajectory = Trajectory( ElasticArraySARTSTraces(; state = Int64 => (), action = Int64 => (), reward = Float64 => (), terminal = Bool => (), ), DummySampler(), InsertSampleRatioController(), )Trajectory{EpisodesBuffer{(:state, :next_state, :action, :reward, :terminal), Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, ElasticArraySARTSTraces{Tuple{MultiplexTraces{(:state, :next_state), Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Int64}, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}, 5, Tuple{Int64, Int64, Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}}, Vector{Int64}, BitVector}, DummySampler, InsertSampleRatioController, typeof(identity)}(@NamedTuple{state::Int64, next_state::Int64, action::Trace{ElasticArrays.ElasticVector{Int64, Vector{Int64}}, SubArray{Int64, 0, ElasticArrays.ElasticVector{Int64, Vector{Int64}}, Tuple{Int64}, true}}, reward::Trace{ElasticArrays.ElasticVector{Float64, Vector{Float64}}, SubArray{Float64, 0, ElasticArrays.ElasticVector{Float64, Vector{Float64}}, Tuple{Int64}, true}}, terminal::Trace{ElasticArrays.ElasticVector{Bool, Vector{Bool}}, SubArray{Bool, 0, ElasticArrays.ElasticVector{Bool, Vector{Bool}}, Tuple{Int64}, true}}}[], DummySampler(), InsertSampleRatioController(1.0, 1, 0, 0), identity)julia> agent = Agent( policy = RandomPolicy(), trajectory = trajectory )Agent( RandomPolicy{Nothing, Random.TaskLocalRNG}(nothing, Random.TaskLocalRNG()), )julia> run(agent, env, StopAfterNEpisodes(10), TotalRewardPerEpisode())TotalRewardPerEpisode{Val{true}, Float64}([1.0, -1.0, 1.0, -1.0, -1.0, 1.0, 1.0, 1.0, 1.0, -1.0], 0.0, true)
Here the Trajectory is used to store the State, Action, Reward, is_Terminated info during interactions with the environment.