Establish a General Pipeline for Offline Reinforcement Learning Evaluation
In recent years, there have been several breakthroughs in the field of Reinforcement Learning with numerous practical applications where RL bots have been able to achieve superhuman performance. This is also reflected in the industry where several cutting edge solutions have been developed based on RL (Tesla Motors, AutoML, DeepMind data center cooling solutions just to name a few).
One of the most prominent challenges in RL is the lack of reliable environments for training RL agents. Offline RL has played a pivotal role in solving this problem by removing the need for the agent to interact with the environment to improve its policy over time. This brings forth the problem of not having reliable tests to verify the performance of RL algorithms. Such tests are facilitated by standard datasets (RL Unplugged, D4RL and An Optimistic Perspective on Offline Reinforcement Learning) that are used to train Offline RL agents and benchmark against other algorithms and implementations. ReinforcementLearningDatasets.jl provides a simple solution to access various standard datasets that are available for Offline RL benchmarking across a variety of tasks.
Another problem in Offline RL is Offline Model Selection. For this, there are numerous policies that are available in Benchmarks for Deep Off-Policy Evaluation. ReinforcementLearningDatasets.jl will also help in loading policies that will aid in model selection in ReinforcementLearning.jl package.
Create a package called ReinforcementLearningDatasets.jl that would aid in loading various standard datasets and policies that are available. Currently supported datasets are:
Make standard policies in Benchmarks for Deep Off-Policy Evaluation to be available in RLDatasets.jl.
Implement an Off Policy Evaluation method and select between a number of standard policies for a particular task using RLDatasets.jl.
The following are the future work that are possible in this project.
Parallel loading and partial loading of datasets.
Add support for environments that are not supported by GymEnvs -> Flow and CARLA.
Add support for datasets in Flow and CARLA envs.
Add support for creating, storing and loading custom made datasets.
test-train split functionality for datasets.
Cross validation and grid search.
Enable features that make a particular algorithm based on the requirements of the env.
evaluator function that performs evaluation (can be on policy or off policy)
Metrics as hooks. Refer Metrics
Refer the following discussion for more ideas.
| Date | Goals |
|---|
| 07/01 - 07/14 | Brainstorm various ideas that are possible for the implementation of RLDatasets.jl and finalize the key features. |
| 07/15 - 07/20 | Made a basic julia wrapper for d4rl environments and add some tests |
| 07/21 - 07/30 | Implemented d4rl and d4rl-pybullet datasets |
| 07/31 - 08/06 | Implemented Google Research DQN Replay Datasets |
| 08/07 - 08/14 | Implemented RL Unplugged atari datasets, setup the docs, added README.md. Made the package more user friendly. Make the mid-term report |
| 08/15 - 08/30 | Added bsuite datasets, polished the interface, finalized the structure of the codebase. Fixed problem with windows |
| 09/01 - 09/15 | Added support for policy loading from Benchmarks for Deep Off-Policy Evaluation |
| 09/16 - 09/30 | Researched about OPE methods, implemented FQE and test basic performance. Completed the final-term report |
There are some changes to the original timeline based on a few time constraints but the basic objectives of the project are accomplished.
The documentation for this package is available in RLDatasets.jl. Do check it out for more details.
To install the ReinforcementLearningDatasets.jl package use the following command in julia's pkg mode.
pkg> add https://github.com/JuliaReinforcementLearning/ReinforcementLearning.jl:src/ReinforcementLearningDatasets
Added support for D4RL datasets with all features loaded in the returned type.
Credits: D4RL
using ReinforcementLearningDatasets
ds = dataset(
"hopper-medium-replay-v0";
repo="d4rl")
The type (D4RLDataSet) returned by dataset is an Iterator that returns batches of data based on the requirement that is specified.
Now, you could take the values of the ds or iterate over it.
julia> batches = Iterators.take(ds, 2)
D4RLDataSet{StableRNGs.LehmerRNG}(Dict{Symbol, Any}(:reward => Float32[0.9236555, 0.8713692, 0.92237693, 0.9839225, 0.91540813, 0.8331875, 0.8102179, 0.78385466, 0.7304337, 0.6942671 … 5.0350657, 5.005931, 4.998442, 4.986662, 4.9730926, 4.9638906, 4.9503803, 4.9326644, 4.8952913, 4.8448896], :state => Float32[1.2521756 1.2519351 … 0.72994494 0.7145643; 0.00026937472 -0.0048946342 … 0.13946348 0.15210924; … ; 0.002733759 -1.1853988 … -0.06101464 -0.045892276; -0.0028058232 0.08466121 … -1.4235892 -1.0558393], :action => Float32[-0.67060924 -0.39061046 … -0.15234122 -0.1382414; -0.9329903 0.65977097 … 0.9518685 0.9666188; 0.010210991 -0.073685646 … 0.24721281 -0.2440847], :terminal => Int8[0, 0, 0, 0, 0, 0, 0, 0, 0, 0 … 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]), "d4rl", 200919, 256, (:state, :action, :reward, :terminal, :next_state), StableRNGs.LehmerRNG(state=0x000000000000000000000000000000f7), Dict{String, Any}("timeouts" => Int8[0, 0, 0, 0, 0, 0, 0, 0, 0, 0 … 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), true)
julia> typeof(batches)
Base.Iterators.Take{D4RLDataSet{StableRNGs.LehmerRNG}}
julia> batch = collect(batches)[1]
NamedTuple{(:state, :action, :reward, :terminal, :next_state), Tuple{Matrix{Float32}, Matrix{Float32}, Vector{Float32}, Vector{Int8}, Matrix{Float32}}}
julia> size(batch[:state])
(11, 256)
Added support for datasets released in d4rl-pybullet. This enables testing the agents in complex environments without Mujoco license.
Credits: d4rl-pybullet
using ReinforcementLearningDatasets
ds = dataset(
"hopper-bullet-mixed-v0";
repo="d4rl-pybullet",
)
samples = Iterators.take(ds, 2)
The output is similar to D4RL.
Added support for Google Research Atari DQN Replay Datasets. Currently, the datasets are directly loaded into the RAM and therefore, it is advised to be used only with sufficient amount of RAM (around 20 GB of free space). Support for lazy parallel loading in a Channel will be given soon.
Credits: DQN Replay Datasets
using ReinforcementLearningDatasets
ds = dataset(
"pong",
1,
[1, 2]
)
samples = Iterators.take(ds, 2)
The output is similar to D4RL.
Added support for RL Unplugged atari datasets. The datasets that are stored in the form of .tfrecord are fetched into julia. Lazy loading with multi threading is implemented. This implementation is based on previous work in TFRecord.jl.
Credits: RL Unplugged
using ReinforcementLearningDatasets
ds = ds = rl_unplugged_atari_dataset(
"Pong",
1,
[1, 2]
)
The type that is returned is a Channel{AtariRLTransition} which returns batches with the given specifications from the buffer when take! is used. The point to be noted here is that it takes seconds to load the datasets into the Channel and the loading is highly customizable.
julia> ds = ds = rl_unplugged_atari_dataset(
"Pong",
1,
[1, 2]
)
[ Info: Loading the shards [1, 2] in 1 run of Pong with 4 threads
Progress: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| Time: 0:00:08
Channel{ReinforcementLearningDatasets.AtariRLTransition}(12) (12 items available)
It also supports lazy downloading of the datasets based on the shards that are required by the user. In this case only gs://rl_unplugged/atari/Pong/atari_Pong_run_1-00001-of-00100 and gs://rl_unplugged/atari/Pong/atari_Pong_run_1-00002-of-00100 will only be downloaded with permissions from the user. If it is already present the dataset is located using DataDeps.jl.
The loading time for batches is also very minimal.
julia> @time batch = take!(ds)
0.000011 seconds (1 allocation: 80 bytes)
julia> typeof(batch)
ReinforcementLearningDatasets.AtariRLTransition
julia> typeof(batch.state)
Array{UInt8, 4}
julia> size(batch.state)
(84, 84, 4, 256)
julia> size(batch.reward)
(256,)
The challenge that was faced during the first week was to chart out a direction for RLDatasets.jl. I researched the implementations of the pipeline in d3rlpy, TF.data.Dataset etc and then narrowed down some inspiring ideas in the discussion.
Later, I made the implementation as a wrapper around d4rl python library, which was discarded as it did not align with the purpose of the library of being lightweight and not requiring a Mujoco license for usage of open source datasets. A wrapper would also not give the fine grained control that we could get if we load the datasets natively.
We decided to use DataDeps.jl for registering, tracking and locating datasets without any hassle. DataDeps.jl is a package that helps make data wrangling code more reusable and was crucial in making RLDatasets.jl seamless.
What I learnt here was how to make a package, manage its dependencies and choose which package would be the right fit for the job. I also learnt about Iterator interfaces in julia to convert the type (that is output by the dataset function) into an Iterator. d4rl-pybullet was also implemented in a similar fashion.
Implementation of Google Research Atari DQN Replay Datasets was harder because it was quite a large dataset and even one shard didn't fit into memory of my machine. I also had to figure out how the data was stored and how to retrieve it. Initially, I planned to use GZip.jl to unpack the gzip files and use NPZ.jl to read the files. Since, NPZ didn't support reading from GZipStream by itself, I had to adapt the functions in NPZ to read the stream. Later, we decided to use CodecZlib to get a decompressed buffer channel output which was natively supported by NPZ. We also had to test it internally and skip the CI test because CI wouldn't be able to handle the dataset. Exploring the possibility of lazy loading of the files that are available and enabling it is also within the scope of the project.
For supporting RL Unplugged dataset I had to learn about .tfrecord files, Protocol Buffers, buffered Channels and julia multi threading which was used in a lot of occasions. It took some time to grasp all the concepts but the final implementation, however, was based on already existing work in TFRecord.jl.
All of this work wouldn't have been possible without the patient mentoring and vast knowledge of my mentor Jun Tian, who has been pivotal in the design and implementation of the package. His massive experience and beautifully written code has provided a lot of inspiration to the making of this package. His amicable nature and commitment to the users of the package by providing timely and detailed explanations to any issues or queries related to the package despite his time constraints, has provided a long standing example as a developer and as a person. I also thank all the developers of the packages that RLDatasets.jl depends upon.
The src directory hosts the working logic of the package.
src
├─ ReinforcementLearningDatasets.jl
├─ atari
│ ├─ atari_dataset.jl
│ └─ register.jl
├─ common.jl
├─ d4rl
│ ├─ d4rl
│ │ └─ register.jl
│ ├─ d4rl_dataset.jl
│ └─ d4rl_pybullet
│ └─ register.jl
├─ init.jl
└─ rl_unplugged
├─ atari
│ ├─ register.jl
│ └─ rl_unplugged_atari.jl
└─ util.jl
The directory for handling each dataset would consist of two files. The register.jl that would register the DataDeps that are required and another file that is responsible for loading the datasets. The init functions are called in the project __init__ for registering right after it is imported.
function __init__()
RLDatasets.d4rl_init()
RLDatasets.d4rl_pybullet_init()
RLDatasets.atari_init()
RLDatasets.rl_unplugged_atari_init()
end
The register.jl for d4rl dataset is located in src/d4rl/d4rl which registers the DataDeps. The following is an example code for the registration.
function d4rl_init()
repo = "d4rl"
for ds in keys(D4RL_DATASET_URLS)
register(
DataDep(
repo*"-"* ds,
"""
Credits: https://arxiv.org/abs/2004.07219
The following dataset is fetched from the d4rl.
The dataset is fetched and modified in a form that is useful for RL.jl package.
Dataset information:
Name: $(ds)
$(if ds in keys(D4RL_REF_MAX_SCORE) "MAXIMUM_SCORE: " * string(D4RL_REF_MAX_SCORE[ds]) end)
$(if ds in keys(D4RL_REF_MIN_SCORE) "MINIMUM_SCORE: " * string(D4RL_REF_MIN_SCORE[ds]) end)
""",
D4RL_DATASET_URLS[ds],
)
)
end
nothing
end
The dataset is loaded using ReinforcementLearningDatasets/src/d4rl/d4rl_dataset.jl and is enclosed in a D4RLDataSet type.
struct D4RLDataSet{T<:AbstractRNG} <: RLDataSet
dataset::Dict{Symbol, Any}
repo::String
dataset_size::Integer
batchsize::Integer
style::Tuple
rng::T
meta::Dict
is_shuffle::Bool
end
The dataset function is used to retrieve the files.
function dataset(dataset::String;
style=SARTS,
repo = "d4rl",
rng = StableRNG(123),
is_shuffle = true,
batchsize=256
)
The dataset is downloaded if the dataset is not present and loaded from the local file system using DataDeps.jl
try
@datadep_str repo*"-"*dataset
catch
throw("The provided dataset is not available")
end
path = @datadep_str repo*"-"*dataset
@assert length(readdir(path)) == 1
file_name = readdir(path)[1]
data = h5open(path*"/"*file_name, "r") do file
read(file)
end
The dataset is loaded into D4RLDataSet Iterator and returned. The iteration logic is also implemented in the same file using Iterator interfaces.
Some of the interesting pieces of code used in loading RL Unplugged dataset.
Multi threaded iteration over a Channel{Example} to put! into another Channel{AtariRLTransition}.
ch_src = Channel{AtariRLTransition}(n * tf_reader_sz) do ch
for fs in partition(shuffled_files, n)
Threads.foreach(
TFRecord.read(
fs;
compression=:gzip,
bufsize=tf_reader_bufsize,
channel_size=tf_reader_sz,
);
schedule=Threads.StaticSchedule()
) do x
put!(ch, AtariRLTransition(x))
end
end
end
Multi threaded batching using a parallel loop where each thread loads the batches into Channel{AtariRLTransition}.
res = Channel{AtariRLTransition}(n_preallocations; taskref=taskref, spawn=true) do ch
Threads.@threads for i in 1:batchsize
put!(ch, deepcopy(batch(buffer_template, popfirst!(transitions), i)))
end
end
The following is the final term evaluation report of "General Pipeline for Offline Reinforcement Learning Evaluation Report" in OSPP. Details of all the work that has been done after the mid-term evaluation and some explanation on the current status of the package are given. Some exciting work that is possible based on this project is also given.
Polished and finalized the structure of the package. Improved usability by updating the docs accordingly.
Fixed the run error that was shown in windows.
Added Bsuite and all DM environments including DeepMind Control Suite Dataset, DeepMind Lab Dataset and DeepMind Locomotion Dataset in RL Unplugged Datasets.
Added Deep OPE models for D4RL datasets.
Researched and implemented FQE for which the basic implementation works but there are some flaws that need to be fixed.
The following work has been done post mid-term evaluation.
It involved work similar to RL Unplugged Atari Datasets which involves multi threaded dataloading. It is implemented using a Ring Buffer for storing and loading batches of data.
Huge thanks to Jun Tian for the implementation.
The RingBuffer is based on having two Channels, one for holding the buffer that contains empty batches (buffers) that can be used later for making batches with data. The results Channel is used for holding batches with data. The current holds the latest result.
mutable struct RingBuffer{T} <: AbstractChannel{T}
buffers::Channel{T}
current::T
results::Channel{T}
end
The RingBuffer is created using the following code. It creates an empty buffers Channel that is then used to fill up results by performing inplace operations for making batches with data.
function RingBuffer(f!, buffer::T;sz=Threads.nthreads(), taskref=nothing) where T
buffers = Channel{T}(sz)
for _ in 1:sz
put!(buffers, deepcopy(buffer))
end
results = Channel{T}(sz, spawn=true, taskref=taskref) do ch
Threads.foreach(buffers;schedule=Threads.StaticSchedule()) do x
f!(x)
put!(ch, x)
end
end
RingBuffer(buffers, buffer, results)
end
Whenever a batch is taken from the buffer, the following code gets called.
function Base.take!(b::RingBuffer)
put!(b.buffers, b.current)
b.current = take!(b.results)
b.current
end
I would have implemented a simpler one channel buffer, but RingBuffer proved to be more effective.
The files are read and the datapoints are put in a Channel.
ch_src = Channel{BSuiteRLTransition}(n * tf_reader_sz) do ch
for fs in partition(files, n)
Threads.foreach(
TFRecord.read(
fs;
compression=:gzip,
bufsize=tf_reader_bufsize,
channel_size=tf_reader_sz,
);
schedule=Threads.StaticSchedule()
) do x
put!(ch, BSuiteRLTransition(x, game))
end
end
end
The datapoints are then put in a RingBuffer which is returned.
res = RingBuffer(buffer;taskref=taskref, sz=n_preallocations) do buff
Threads.@threads for i in 1:batchsize
batch!(buff, take!(transitions), i)
end
end
The bsuite_params function can be used to get the possible arguments that can be passed into the function.
julia> bsuite_params()
┌ Info: ["cartpole", "catch", "mountain_car"]
│ shards = 0:4
└ type = 3-element Vector{String}: …
To get the dataset rl_unplugged_bsuite_dataset function can be called.
julia> rl_unplugged_bsuite_dataset("cartpole", [1], "full")
Progress: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| Time: 0:00:06
RingBuffer{ReinforcementLearningDatasets.BSuiteRLTransition}(Channel{ReinforcementLearningDatasets.BSuiteRLTransition}(12), ReinforcementLearningDatasets.BSuiteRLTransition(Float32[1.0f-45 1.0f-45 … NaN 0.0; 0.0 0.0 … NaN 0.0; … ; 3.0f-45 4.0f-45 … NaN 9.0f-44; 0.0 0.0 … NaN 0.0], [140269590665616, 140269590665616, 140269590665616,
...
julia> take!(ds)
ReinforcementLearningDatasets.BSuiteRLTransition(Float32[-0.3289344 0.26131696 … -0.015311318 0.49089232; 0.31783995 -1.2033445 … 0.04303875 -0.24614102; … ; -0.27250051 1.0421202 … -0.17690773 0.2694671; 0.697 0.805 … 0.009 0.955], [0, 0, 0, 0, 0, 1, 1, 0, 0, 1 … 2, 0, 1, 0, 2, 0,
...
The DM datasets load and work similarly to bsuite datasets. Since, I made one file to manage DM Control, DM Lab and DM Locomotion, there had to be a lot of post processing work to handle all the edge cases presented by each of the dataset.
The types also had to be created based on the individual datasets so that the code is good at loading efficiently.
function make_transition(example::TFRecord.Example, feature_size::Dict{String, Tuple})
f = example.features.feature
observation_dict = Dict{Symbol, AbstractArray}()
next_observation_dict = Dict{Symbol, AbstractArray}()
transition_dict = Dict{Symbol, Any}()
for feature in keys(feature_size)
if split(feature, "/")[1] == "observation"
ob_key = Symbol(chop(feature, head = length("observation")+1, tail=0))
if split(feature, "/")[end] == "egocentric_camera"
cam_feature_size = feature_size[feature]
ob_size = prod(cam_feature_size)
observation_dict[ob_key] = reshape(f[feature].bytes_list.value[1][1:ob_size], cam_feature_size...)
next_observation_dict[ob_key] = reshape(f[feature].bytes_list.value[1][ob_size+1:end], cam_feature_size...)
else
if feature_size[feature] == ()
observation_dict[ob_key] = f[feature].float_list.value
else
ob_size = feature_size[feature][1]
observation_dict[ob_key] = f[feature].float_list.value[1:ob_size]
next_observation_dict[ob_key] = f[feature].float_list.value[ob_size+1:end]
end
end
elseif feature == "action"
ob_size = feature_size[feature][1]
action = f[feature].float_list.value
transition_dict[:action] = action[1:ob_size]
transition_dict[:next_action] = action[ob_size+1:end]
elseif feature == "step_type"
transition_dict[:terminal] = f[feature].float_list.value[1] == 2
else
ob_key = Symbol(feature)
transition_dict[ob_key] = f[feature].float_list.value[1]
end
end
state_nt = (state = NamedTuple(observation_dict),)
next_state_nt = (next_state = NamedTuple(next_observation_dict),)
transition = NamedTuple(transition_dict)
merge(transition, state_nt, next_state_nt)
end
The batch is made based on the internal types that are available based on the specific dataset.
julia> rl_unplugged_dm_dataset("fish_swim", [1]; type="dm_control_suite")
Progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| Time: 0:00:02
RingBuffer{NamedTuple{(:reward, :episodic_reward, :discount, :state, :next_state, :action, :next_action, :terminal), Tuple{Vector{Float32}, Vector{Float32}, Vector{Float32}, NamedTuple{(:joint_angles, :upright, :target, :velocity), NTuple{4, Matrix{Float32}}}, NamedTuple{(:joint_angles, :upright, :target, :velocity), NTuple{4, Matrix{Float32}}}, Matrix{Float32}, Matrix{Float32}, Vector{Bool}}}}(Channel{NamedTuple{(:reward, :episodic_reward, :discount, :state, :next_state, :action, :next_action, :terminal), Tuple{Vector{Float32}, Vector{Float32}, Vector{Float32}, NamedTuple{(:joint_angles, :upright, :target, :velocity), NTuple{4, Matrix{Float32}}}, NamedTuple{(:joint_angles, :upright, :target, :velocity), NTuple{4, Matrix{Float32}}}, Matrix{Float32}, Matrix{Float32}, Vector{Bool}}}}(12), (reward = Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -3.4009038f-36, 4.5764f-41 … 0.0, 0.0, 2.3634088f-28, 4.5765f-41, 1.1692183f-34, 4.5764f-41, 0.0, 0.0,
...
Support is given for D4RL policies provided in Deep OPE.
The policies that are given here are loaded using d4rl_policy function.
The policies are loaded into a D4RLGaussianNetwork which will be integrated into GaussianNetwork in RLCore soon.
Base.@kwdef struct D4RLGaussianNetwork{P,U,S}
pre::P = identity
μ::U
logσ::S
end
The network returns the a, μ based on the parameters that are passed into it.
function (model::D4RLGaussianNetwork)(
state::AbstractArray;
rng::AbstractRNG=MersenneTwister(123),
noisy::Bool=true
)
x = model.pre(state)
μ, logσ = model.μ(x), model.logσ(x)
if noisy
a = μ + exp.(logσ) .* Float32.(randn(rng, size(μ)))
else
a = μ + exp.(logσ)
end
a, μ
end
The weights are loaded using the following code.
To know the real life performance of the networks an auxiliary function deep_ope_d4rl_evaluate is also given which gives the unicode plot showing the performance of the policy. The code is given here.
The params needed for loading the policies can be obtained using d4rl_policy_params
julia> d4rl_policy_params()
┌ Info: Set(["relocate", "maze2d_large", "antmaze_umaze", "hopper", "pen", "antmaze_medium", "walker", "hammer", "antmaze_large", "maze2d_umaze", "maze2d_medium", "ant", "door", "halfcheetah"])
│ agent = 2-element Vector{String}: …
└ epoch = 0:10
Sometimes the expected policy may not be available. So, it is always better to check which ones are available using ReinforcementLearningDatasets.D4RL_POLICIES.
julia> policy = d4rl_policy("hopper", "online", 3)
D4RLGaussianNetwork{Flux.Chain{Tuple{Flux.Dense{typeof(NNlib.relu), Matrix{Float32}, Vector{Float32}}, Flux.Dense{typeof(NNlib.relu), Matrix{Float32}, Vector{Float32}}}}, Flux.Chain{Tuple{Flux.Dense{typeof(identity), Matrix{Float32}, Vector{Float32}}}}, Flux.Chain{Tuple{Flux.Dense{typeof(identity), Matrix{Float32}, Vector{Float32}}}}}(Chain(Dense(11, 256, relu), Dense(256, 256, relu)), Chain(Dense(256, 3)), Chain(Dense(256, 3)))
The policy will return the a and μ for a state that is given.
deep_ope_d4rl_evaluate is a helper function that helps visualize the performance of the agent. The more the epoch number, the better the performance.
julia> deep_ope_d4rl_evaluate("halfcheetah", "online", 3)
Progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| Time: 0:00:01
halfcheetah-medium-v0 scores
+----------------------------------------+
8100 | .| scores
| .'|
| . .' |
| .' : .' |
| .' : :. : |
| .' : .' : .' |
|.' '. : : .' |
score | : : '. .' |
| '. .' '. : |
| : : : : |
| ': : : |
| : .' |
| '.: |
| ' |
7400 | |
+----------------------------------------+
1 10
episode
julia> deep_ope_d4rl_evaluate("halfcheetah", "online", 10)
Progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| Time: 0:00:01
halfcheetah-medium-v0 scores
+----------------------------------------+
12000 | . | scores
|''''..........''''. :. :''''|
| : :'. : |
| : .' '. : |
| '. : : : |
| : : :: |
| : .' ' |
score | '. : |
| : : |
| : .' |
| '. : |
| : : |
| :.' |
| :: |
2000 | : |
+----------------------------------------+
1 10
episode
A major amount of time was spent on researching about OPE methods of which FQE was the most appropriate given that the use case is Deep Reinforcement Learning.
Batch Policy Learning under Constraints introduces the FQE and uses it for offline reinforcement learning under constraints and achieves remarkable results by calculating new constraint cost functions with the datasets. The algorithm that is implemented in RLZoo is similar to the one that is proposed here.

The implementation in RLZoo is based on Hyperparameter Selection for Offline Reinforcement Learning. This is very similar to the algorithm that we discussed earlier. The paper uses OPE as a method for offline hyper paramater selection.
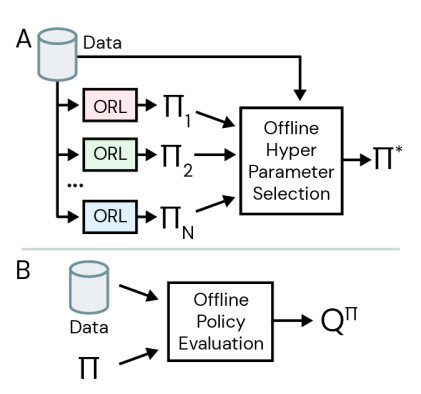
The average of values calculated by FQE based on initial states can be taken as the reward that the policy would gain from the environment. So, the same can be used for online hyper parameter selection.
The pseudocode for the implementation and the objective function are as follows.

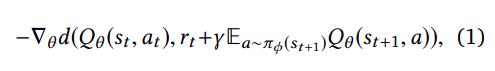
Function parameters for the implementation.
mutable struct FQE{
P<:GaussianNetwork,
C<:NeuralNetworkApproximator,
C_T<:NeuralNetworkApproximator,
R<:AbstractRNG,
} <: AbstractLearner
policy::P
q_network::C
target_q_network::C_T
n_evals::Int
γ::Float32
batchsize::Int
update_freq::Int
update_step::Int
tar_update_freq::Int
rng::R
loss::Float32
end
The update function for the learner is a simple critic update based on the following procedure.
function RLBase.update!(l::FQE, batch::NamedTuple{SARTS})
policy = l.policy
Q, Qₜ = l.q_network, l.target_q_network
D = device(Q)
s, a, r, t, s′ = (send_to_device(D, batch[x]) for x in SARTS)
γ = l.γ
batchsize = l.batchsize
loss_func = Flux.Losses.mse
q′ = Qₜ(vcat(s′, policy(s′)[1])) |> vec
target = r .+ γ .* (1 .- t) .* q′
gs = gradient(params(Q)) do
q = Q(vcat(s, reshape(a, :, batchsize))) |> vec
loss = loss_func(q, target)
Zygote.ignore() do
l.loss = loss
end
loss
end
Flux.Optimise.update!(Q.optimizer, params(Q), gs)
if l.update_step % l.tar_update_freq == 0
Qₜ = deepcopy(Q)
end
end
The implementation is still a work in progress because of some sampling error. But the algorithm that I implemented without RL.jl framework works as expected.
Policy => CRR Policy
Env => PendulumEnv
q_networks => Two 64 neuron layers with n_s+n_a input neurons and 1 output neuron.
optimizer => Adam(0.005)
loss => Flux.Losses.mse
γ => 0.99
batch_size => 256
update_freq, update_step => 1
tar_update_freq => 256
number of training steps => 40_000
The values evaluated by FQE for 100 initial states.

mean=-243.0258f0
The values obtained by running the agent in the environment for 100 iterations.
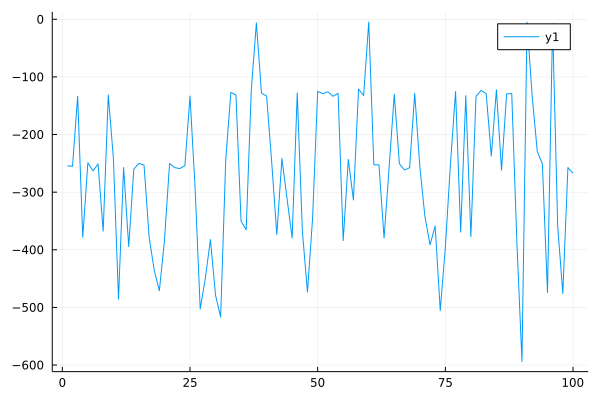
mean=-265.7068139137983
The foundations of RLDatasets.jl package has been laid during the course of the project. The basic datasets except for Real World Datasets from RL Unplugged have been supported. Furthermore, D4RL policies have been successfully loaded and tested. The algorithm for FQE has been tried out with a minor implementation detail pending.
With the completion of FQE the four requirements of OPE as laid out by Deep OPE will be completed for D4RL.

Equipping RL.jl with RLDatasets.jl is a key step in making the package more industry relevant because different offline algorithms can be compared with respect to a variety of standard offline dataset benchmarks. It is also meant to improve the implementations of existing offline algorithms and make it on par with the SOTA implementations. This package provides a seamless way of downloading and accessing existing datasets and also supports loading datasets into memory with ease, which if implemented separately, would be tedious for the user. It also incorporates policies that can be useful for testing Off Policy Evaluation Methods.
There are several exciting work that are possible from this point.